




Bee Classification using Convolutional Neural Network (CNN)
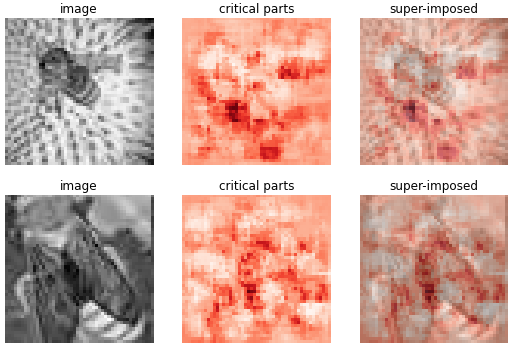
I worked on this project to compete in The Metis Challenge: Naive Bees Classifier competition. The goal of the competition is to determine the genus of the bee - Apis (honey bee) or Bombus (bumble bee) based on photographs of the insects.
I implemented a Convolutional Neural Network (CNN) architecture using Theano, trained it to extract features and determine genus of the bee based on the photographs. Before training, data was preprocessed by resizing, translating, rotating and flipping every image. This additional training data helped reduce overfitting and improved the model invariance. With this architecture and preprocessing, I achieved an accuracy of 81.9% with just 25 iterations of training on CPU.
CodeQuestion Answering System
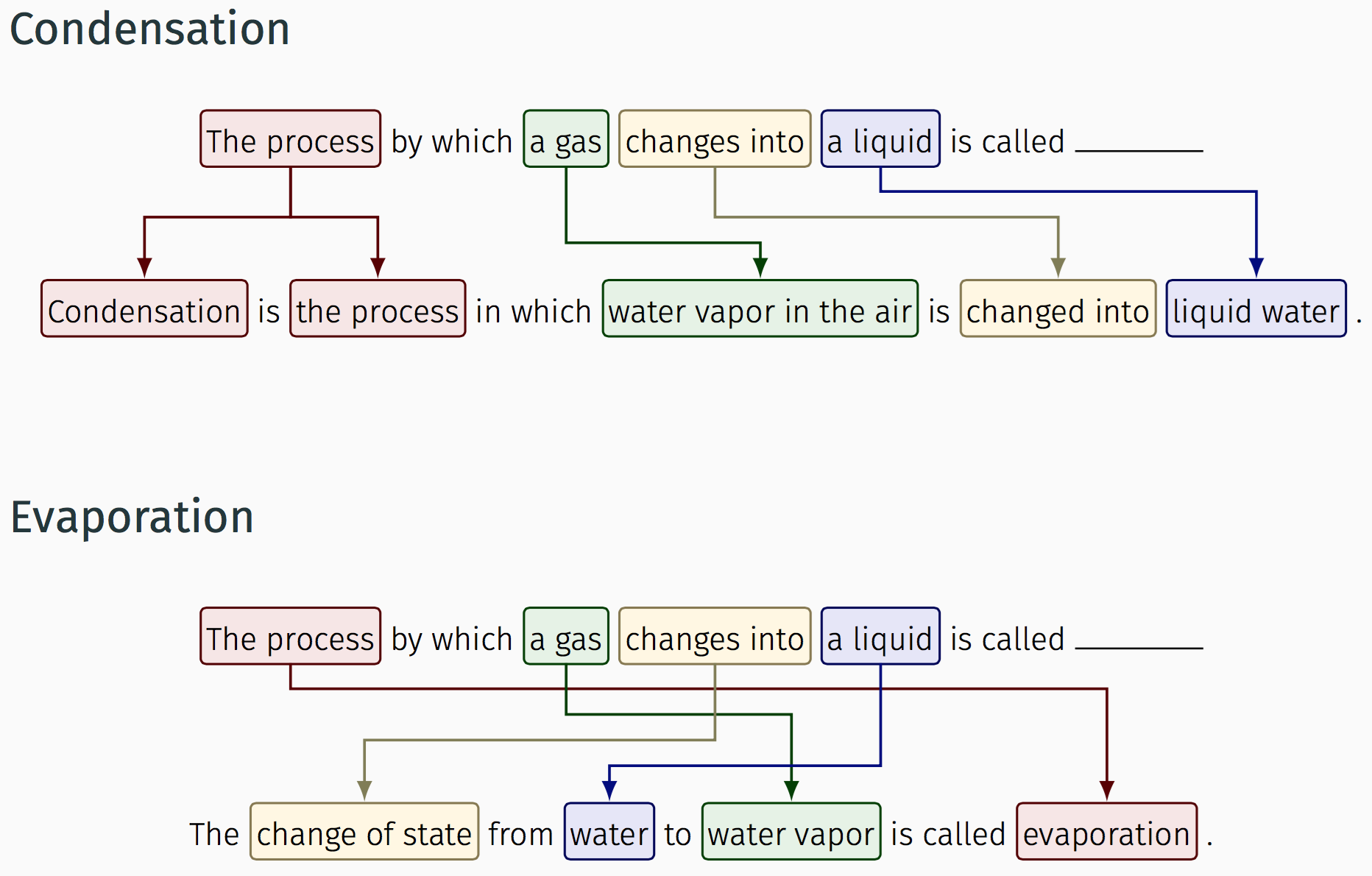
The goal of this project is to build a question answering system that uses alignment over semantic roles to answer and pass a 4th grade science exam.
The baseline solution uses word overlap between question and answer sentences to predict the probable answer. In this baseline method, scoring is done by dividing number of common tokens between question and answer sentences with number of tokens in the question sentence. This system answered 48% of the questions. I tried the following two methods in order to improve upon the baseline method.
Role Aligner: Run SRL on question and answer sentences and align the roles in the question with roles in the answer using textual entailment score. This system answered 62.5% of the questions.Jacana Align: Use Conditional Random Field based token alignment using Jacana Aligner. This system answered 44% of the questions (One of the reasons for low accurcay is that the system was trained on news corpus while questions in the dataset were regarding biological processes).
Predicting the Super Bowl and College Football Champions of 2015
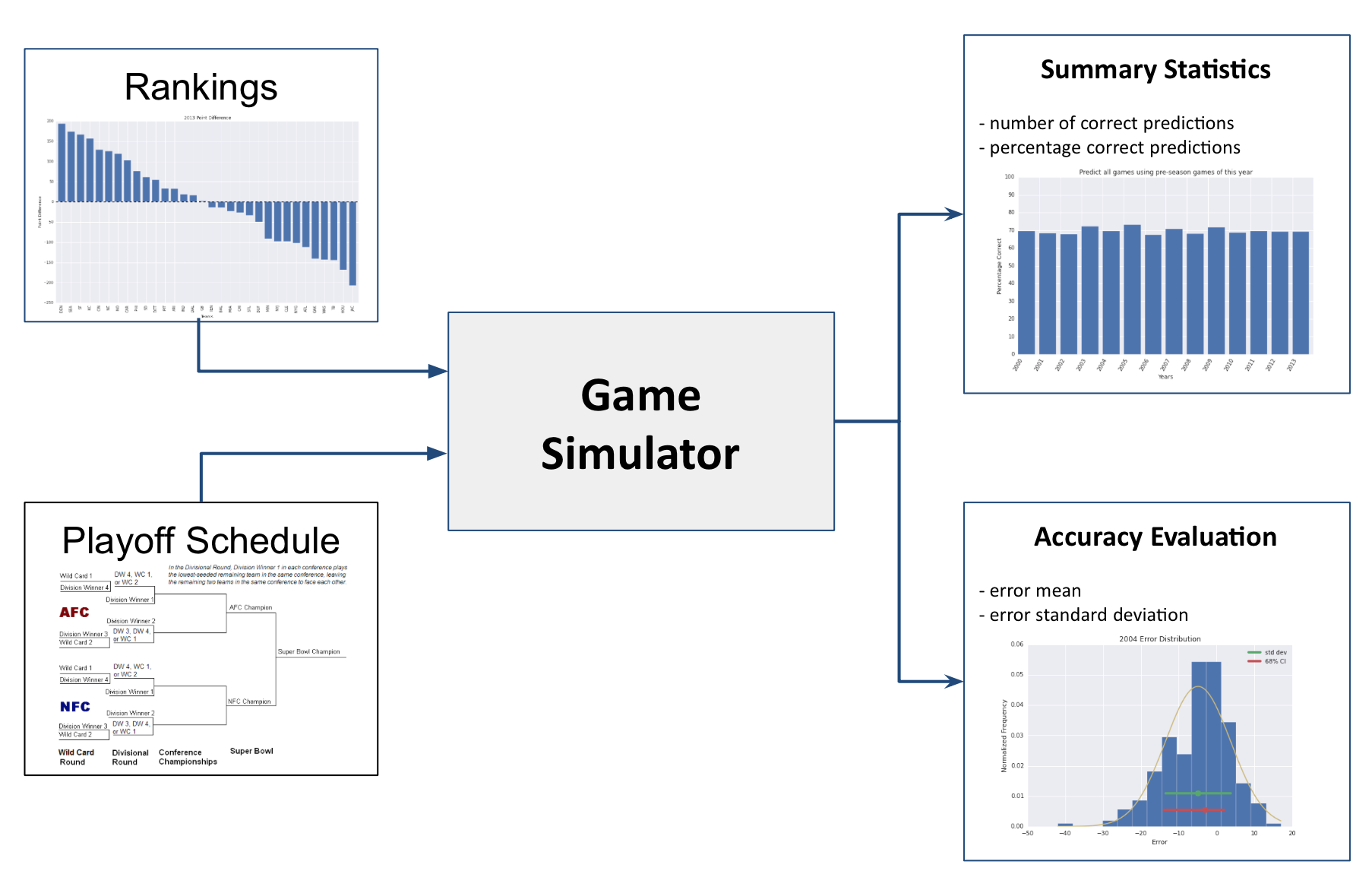
The goal of this project is to build machine learning models to predict the winners of 2015 Super Bowl and the College Football Championship using historical data.
We have predicted the outcome of football matches entirely using the knowledge of previous game statistics. We have used three different models to do this:
Baseline model: "Point Score Difference Model". In this model we use the score difference to predict winners of future games.Linear Regression Model: In this model, we use linear regression to predict the point difference for each game.PageRank Model: Here, we model the game data as a graph with nodes as teams and edges as score differences between the teams. We then use PageRank on this game graph to rank all the teams. This ranking is used to predict winners of future games.
More information about the project can be found here.
Code ReportPredicting Yelp review rating stars from review text

The goal of this project is to predict reviews' star ratings on Yelp from review text.
We have built the following models that perform text analysis on review data to predict the rating stars.
Baseline Model: The most common rating, 4 stars, is the rating predicted by this model for all the reviews.Term Frequency Model: In this model we use frequency of word occurrence to predict the review rating.LDA + Sentiment Model: This model predicts rating using Latent Dirichlet Allocation (LDA) with an added sentiment layer by extracting topics and sentiment associated with the review from review text.NMF + Sentiment Model: In this model, we predict review rating using Non-negative Matrix Factorization (NMF) with an added sentiment layer by extracting topics and sentiment associated with the review from review text.
We have achieved an accuracy of 61% in predicting review rating stars.
Code Report PresentationPredicting facial beauty using Convolutional Neural Network (CNN)
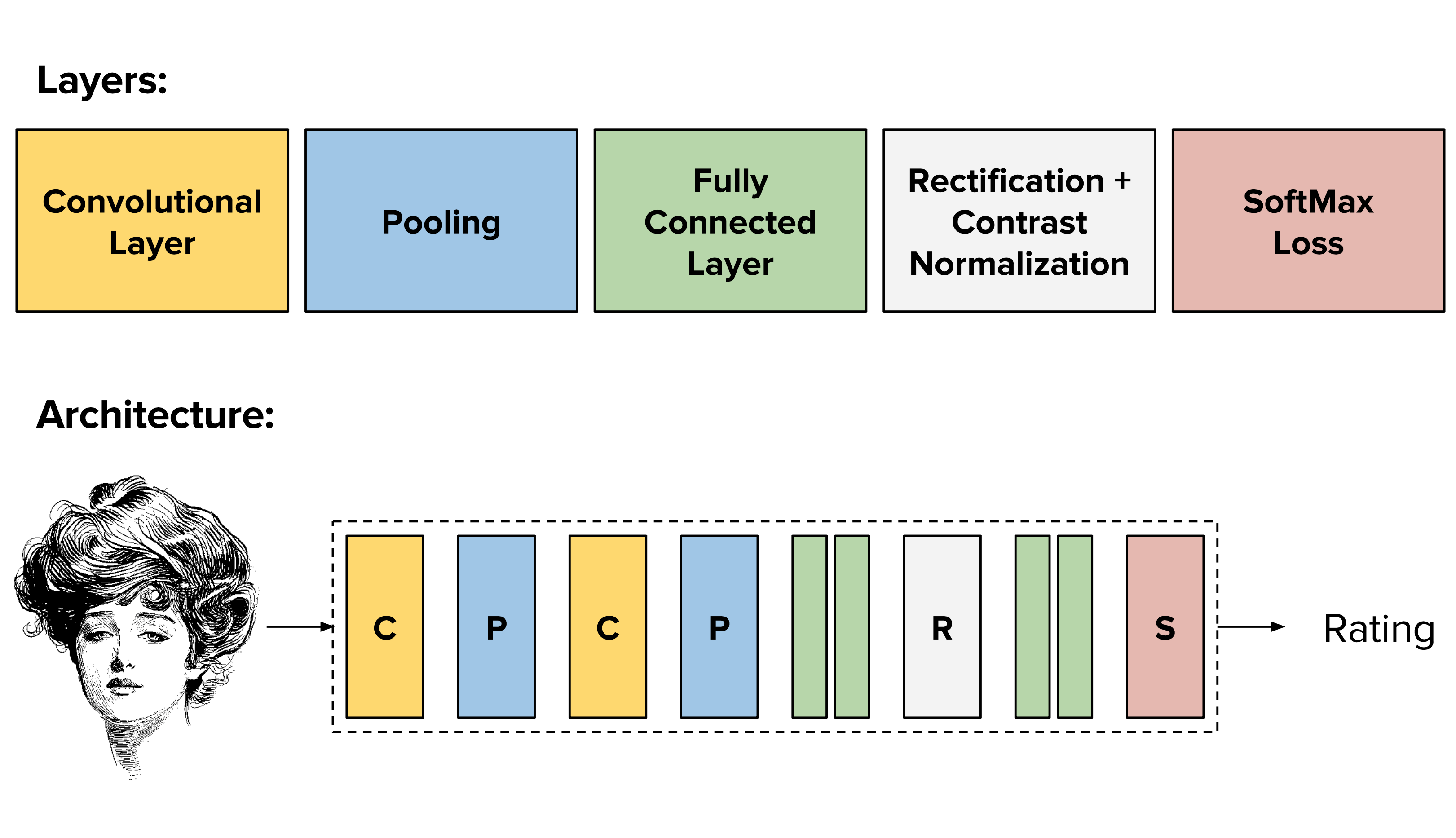
Aim of this project is, for every image with a face of a human, rate the beauty of the face, using a Convolutional Neural Network (CNN). This is done without considering any landmark features. Thus, detecting the features, training them, as well as testing would be done using CNN.
We configured a deep learning CNN using Caffe (a fast framework for deep learning) and trained it to classify faces into one of the 5 classes based on facial beauty.
The trained model predicts facial beauty with an accuracy of 50.32%.
Code Report PresentationtMood

This project is developed during Bitcamp Hackathon.
A Pebble app that analyses the sentiment of people around you using twitter feeds at your location. Backend for this project is developed in Python and hosted in pythonanywhere.com with Frontend developed in JavaScript.
- The backend service uses flask web framework for handling requests. It accepts input requests in the form of a JSON array containing list of place names.
- This is then used to get the tweets around the list of places.
- We use sentiment classifier by IBM Alchemy to get the tweet sentiments.
- Then we randomly select 16 tweets along with their sentiments and return it in JSON format.
- It is then used to display 16 smileys on the screen of the watch depending on the sentiment of the tweet.
- On clicking the smiley you can view the complete tweet and also you can shake your watch to view random tweet and its sentiment